Ошибка «504 Gateway Time-out» при обновлении nextcloud


Задача:
---------------------------------------------------------------Выявить причину возникновения ошибки «504 Gateway Time-out» и найти варианты решения
Ошибка появилась при попытке обновить nextcloud при помощи веб-интерфейса.
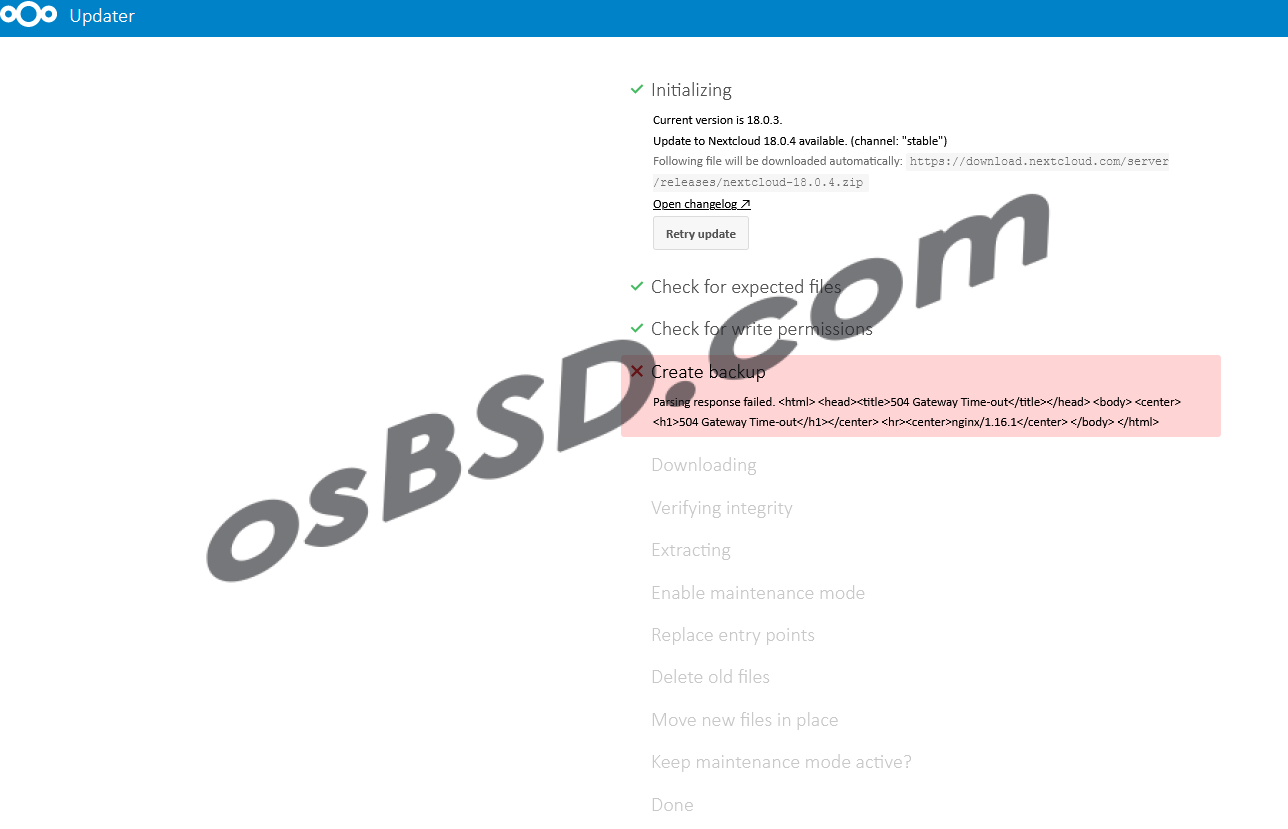
Дословно ошибка «504 Gateway Time-out», означает, что превышено время ожидания ответа от сервера. Из сообщения понятно, что используется веб-сервер nginx. В эту сторону и будем копать. Авторизуемся на сервере при помощи SSH и собираем информацию:
root@cloud:/ # uname -a FreeBSD cloud 12.0-RELEASE FreeBSD 12.0-RELEASE r341666 GENERIC amd64
На сервере операционная система FreeBSD. Это необходимо знать, чтобы понять как дальше действовать, так как команды могут различаться. Это не имеет отношении к проблеме, но проверяем историю входов в систему, и последнюю перезагрузку. Мало ли кто тут был )
root@cloud:/ # last ncuser pts/0 192.168.1.231 Mon Apr 27 00:59 still logged in ncuser pts/0 192.168.1.231 Sun Apr 19 19:07 - 01:37 (06:30) ncuser pts/0 192.168.1.231 Sun Apr 19 15:12 - 15:28 (00:16) ncuser pts/0 192.168.1.231 Sat Apr 18 01:26 - 02:20 (00:53)
Проверяем 10 самых ресурсоёмких приложения в данный момент
root@cloud:/ # top -n 10
last pid: 24968; load averages: 0.44, 0.32, 0.26 up 34+05:36:03 01:06:28
51 processes: 1 running, 49 sleeping, 1 stopped
CPU: 2.0% user, 0.0% nice, 0.5% system, 0.0% interrupt, 97.5% idle
Mem: 857M Active, 5269M Inact, 618M Laundry, 1115M Wired, 579M Buf, 262M Free
ARC: 2105K Total, 808K MFU, 1158K MRU, 32K Anon, 18K Header, 86K Other
216K Compressed, 1846K Uncompressed, 8.55:1 Ratio
Swap: 1024M Total, 673M Used, 351M Free, 65% Inuse
PID USERNAME THR PRI NICE SIZE RES STATE C TIME WCPU COMMAND
24958 root 1 23 0 58M 21M select 0 0:19 5.96% rsync
984 mysql 37 20 0 1470M 1148M select 1 262:08 0.00% mysqld
787 redis 4 20 0 17M 5296K kqread 2 86:46 0.00% redis-server
51562 www 1 52 0 265M 54M accept 2 29:22 0.00% php-fpm
52711 www 1 52 0 265M 56M accept 0 28:38 0.00% php-fpm
120 root 3 20 0 33M 4164K select 0 28:37 0.00% vmtoolsd
808 www 1 20 0 29M 9240K kqread 1 23:55 0.00% nginx
52426 www 1 52 0 329M 118M accept 0 23:18 0.00% php-fpm
51412 www 1 29 0 329M 122M accept 3 22:51 0.00% php-fpm
52712 www 1 21 0 329M 75M accept 0 20:34 0.00% php-fpm
Из всей информации видно, что мало swap. Если в нормальном состоянии используется 65%, есть большой шанс, что при большей нагрузки памяти не хватает. Проверим ещё раз информацию о SWAP
root@cloud:/ # swapinfo Device 1K-blocks Used Avail Capacity /dev/da0s1b 1048544 689440 359104 66% root@cloud:/ # swapinfo -h Device 1K-blocks Used Avail Capacity /dev/da0s1b 1048544 673M 351M 66% root@cloud:/ #
Ищем сообщения об ошибках в системе
root@cloud:/ # dmesg | grep swap swap_pager_getswapspace(31): failed swap_pager_getswapspace(16): failed root@cloud:/ # root@cloud:/ # cat /var/log/messages | grep swap Apr 24 23:10:57 cloud kernel: swap_pager_getswapspace(31): failed Apr 24 23:10:57 cloud kernel: swap_pager_getswapspace(16): failed
Проверяем сколько установлено оперативной памяти на сервере
root@cloud:/ # sysctl hw.physmem
hw.physmem: 8549543936
root@cloud:/ # grep memory /var/run/dmesg.boot
real memory = 8589934592 (8192 MB)
avail memory = 8274640896 (7891 MB)
VMware memory control driver initialized
root@cloud:/ # sysctl -n hw.physmem | awk '{ byte =$1 /1024/1024/1024; print byte " GB" }'
7.96238 GB
root@cloud:/ #
Логично, что исходя из формулы «swap=2*ОЗУ» раздел SWAP должен быть 16 GB. Но не факт что при памяти в 128 GB, необходимо устанавливать SWAP в 256 GB. Это спорный и всегда открытый вопрос.
Смотрим информацию о дисках и имеющихся разделах.
ot@cloud:/ # df -H
Filesystem Size Used Avail Capacity Mounted on
/dev/da0s1a 20G 17G 1.0G 94% /
devfs 1.0k 1.0k 0B 100% /dev
/dev/da1p1 4.8T 2.6T 1.8T 59% /mnt/da1p1
zroot/docker 3.9G 24k 3.9G 0% /usr/docker
zroot 3.9G 24k 3.9G 0% /zroot
root@cloud:/ # swapctl -lhs
Device: Bytes Used:
/dev/da0s1b 1.0G 673M
Total: 1.0G 673M
root@cloud:/ # gpart show
=> 63 41942977 da0 MBR (20G)
63 1 - free - (512B)
64 41942976 1 freebsd [active] (20G)
=> 0 41942976 da0s1 BSD (20G)
0 39845888 1 freebsd-ufs (19G)
39845888 2097088 2 freebsd-swap (1.0G)
=> 40 9663676336 da1 GPT (4.5T)
40 9663676336 1 freebsd-ufs (4.5T)
root@cloud:/ #
Виртуальный системный диск имеет размер 20 GB. Так как это виртуальный сервер на ESXi, заходим в панель администрирования ESXI и увеличиваем его до 30 GB. После сервер необходимо перезагрузить.
Подключаемся и проверяем
root@cloud:/ # gpart show
=> 63 62914497 da0 MBR (30G)
63 1 - free - (512B)
64 41942976 1 freebsd [active] (20G)
41943040 20971520 - free - (10G)
=> 0 41942976 da0s1 BSD (20G)
0 39845888 1 freebsd-ufs (19G)
39845888 2097088 2 freebsd-swap (1.0G)
=> 40 9663676336 da1 GPT (4.5T)
40 9663676336 1 freebsd-ufs (4.5T)
Расширяем место в разделе FreeBSD и проверяем проделанное.
root@cloud:/ # gpart resize -i 1 da0
da0s1 resized
root@cloud:/ # gpart show da0
=> 63 62914497 da0 MBR (30G)
63 1 - free - (512B)
64 62914496 1 freebsd [active] (30G)
root@cloud:/ #
И так на данный момент имеем SWAP размеров в 1 GB, который будем увеличивать до 8 и остальное место отдадим для системы.
Отключаем SWAP
root@cloud:/ # swapinfo Device 1K-blocks Used Avail Capacity /dev/da0s1b 1048544 0 1048544 0% root@cloud:/ # swapoff /dev/da0s1b root@cloud:/ # swapinfo Device 1K-blocks Used Avail Capacity root@cloud:/ #
Удаляем SWAP и проверяем
root@cloud:/ # gpart delete -i 2 da0s1
da0s1b deleted
root@cloud:/ # gpart show
=> 63 62914497 da0 MBR (30G)
63 1 - free - (512B)
64 62914496 1 freebsd [active] (30G)
=> 0 62914496 da0s1 BSD (30G)
0 39845888 1 freebsd-ufs (19G)
39845888 23068608 - free - (11G)
=> 40 9663676336 da1 GPT (4.5T)
40 9663676336 1 freebsd-ufs (4.5T)
root@cloud:/ #
Редактируем vi /etc/fstab
vi /etc/fstab
комментируем строку относящуюся к SWAP
# Device Mountpoint FStype Options Dump Pass# /dev/da0s1a / ufs rw 1 1 #/dev/da0s1b none swap sw 0 0 /dev/da1p1 /mnt/da1p1 ufs rw 0 0 #/dev/da2p1 /mnt/da2p1 ufs rw 0 0
Перезагружаемся в «2. Boot Single user»
Убеждаемся в отсутствии свапа, и проверяем разделы на диске
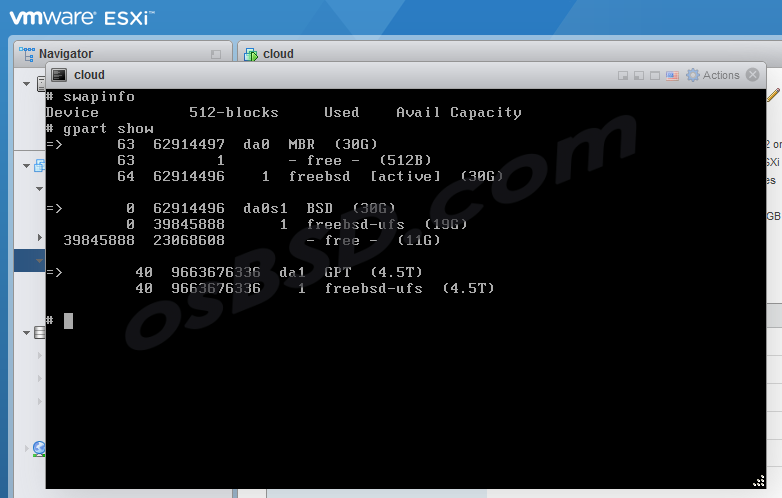
Увеличиваем размер диска до 22G
gpart resize -i 1 -a 4k -s 22G da0s1
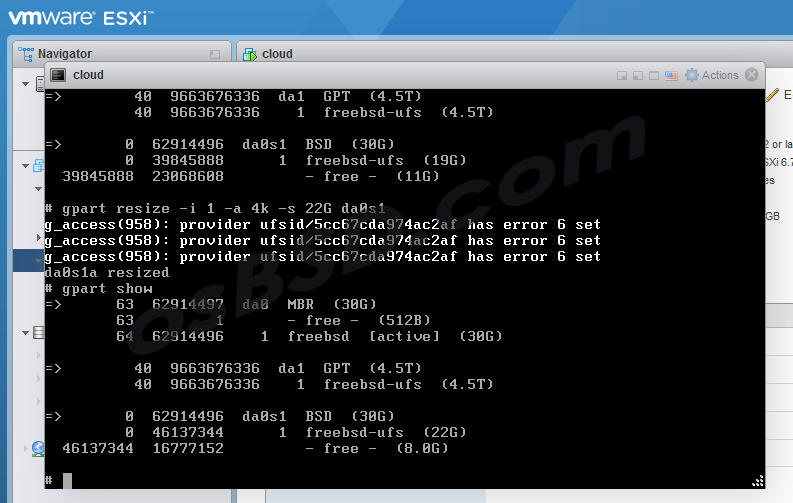
Создаём свап на оставшемся свободном диске
gpart add -t freebsd-swap -a 4k da0s1

Убираем изменения в файле /etc/fstab и перезагружаемся. Если не получилось, перезагружаемся и тогда изменяем fstab и ещё раз перезагружаемся.
Проверяем что всё сделано правильно
root@cloud:/ # swapinfo
Device 1K-blocks Used Avail Capacity
/dev/da0s1b 8388576 0 8388576 0%
root@cloud:/ # gpart show
=> 63 62914497 da0 MBR (30G)
63 1 - free - (512B)
64 62914496 1 freebsd [active] (30G)
=> 0 62914496 da0s1 BSD (30G)
0 46137344 1 freebsd-ufs (22G)
46137344 16777152 2 freebsd-swap (8.0G)
=> 40 9663676336 da1 GPT (4.5T)
40 9663676336 1 freebsd-ufs (4.5T)
root@cloud:/ #



1 комментарий
[…] хватает ли ресурсов серверу. Об этом читаем тут: “Ошибка “504 Gateway Time-out” при обновлении nextcloud” если у вас используется связка nginx, php-fpm и apache, то вы […]